31/03/2022
Martina Miliani

Un algoritmo per analizzare i tweet sui vaccini
A supportare il monitoraggio degli effetti collaterali dei vaccini contro il Covid-19, arriva anche l’intelligenza artificiale. Beatrice Portelli, Simone Scaboro, Edoardo Lenzi, Roberto Tonino, un gruppo di studenti dell’Università di Udine, coadiuvati da tre ricercatori internazionali, Giuseppe Serra, Emmanuele Chersoni ed Enrico Santus, ha creato una piattaforma in grado di analizzare giorno per giorno migliaia di post su Twitter in relazione a ciò che gli utenti pubblicano online sui tre vaccini più diffusi contro il Covid-19: Pfrizer-Biontech, Astrazeneca/Vaxzevria e Moderna.
I dati analizzati
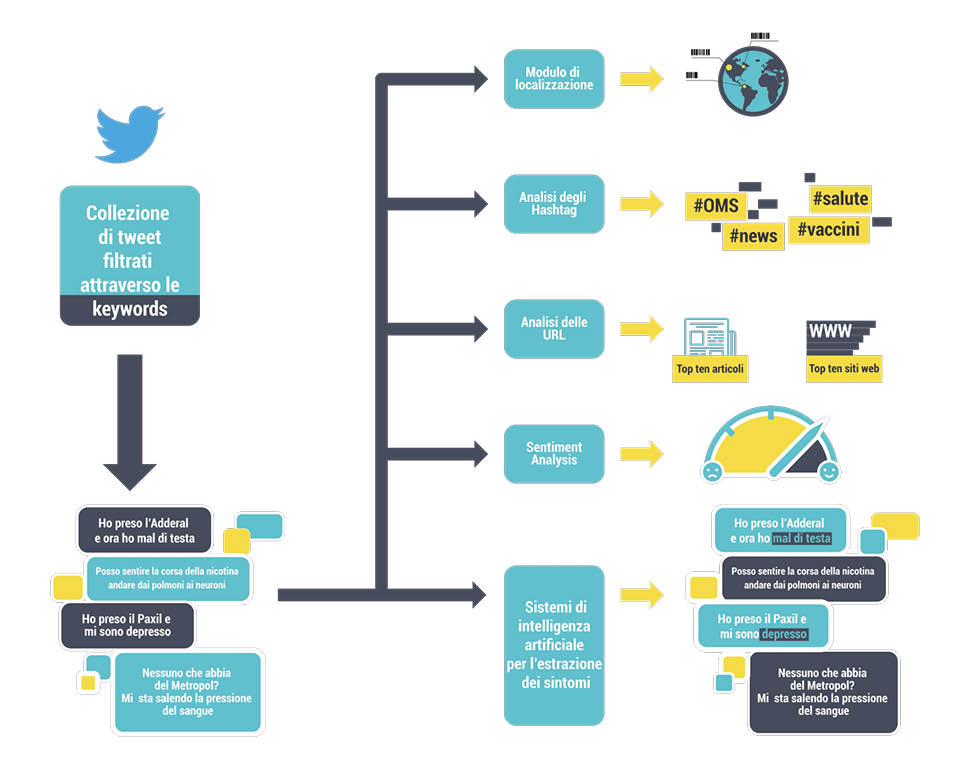
L’algoritmo alla base del funzionamento del portale consente di visualizzare gli hashtag più utilizzati, i link più condivisi e gli effetti collaterali più citati, anche in relazione all’area geografica di provenienza dei post e al sentimento che viene veicolato, ovvero alla polarizzazione negativa o positiva del tweet.
Le aziende farmaceutiche possono così monitorare giorno per giorno come cambia l’opinione pubblica sui vaccini, e possono anche raccogliere dati sugli effetti collaterali più o meno comuni ed eventualmente orientare il testing del farmaco in
una certa direzione.
La piattaforma consente anche di tracciare quali sono i link più condivisi, e quindi avere un’idea delle principali fonti di informazione degli utenti, e osservare anche la difusione di eventuali fake news.
Quello proposto dall’Università di Udine è uno strumento che può quindi guidare anche le istituzioni pubbliche, e in particolar modo quelle sanitarie, a mettere in atto strategie comunicative efficaci allo scopo di aumentare, ad esempio, la copertura vaccinale.
L’idea
Il progetto è nato in seguito alla partecipazione ad uno shared-task, un contest in cui vengono condivisi alcuni dati con la comunità scientifica di riferimento e viene premiato il modello che meglio riesce a
sfruttare quei dati per assolvere un certo compito.
La comunità scientifica di riferimento in questo caso è relativa all’ambito della linguistica computazionale, disciplina che applica tecniche informatiche al linguaggio, tra cui quelle afferenti al Natural Language Processing (NLP), prevedendo anche l’impiego di algoritmi di intelligenza artifciale.
Obiettivo del contest internazionale, dal nome SMM4H 2019 (Social Media Mining for Health Applications), era il riconoscimento nel testo degli effetti collaterali di alcuni farmaci, per cui AILAB – questo il nome del laboratorio dell’Università di Udine coordinato dai professori Giuseppe Serra e Carlo Tasso – ha raggiunto il punteggio migliore tra i modelli in gara.

L’algoritmo
Il modello proposto dall’AILAB dell’Università di Udine impiega una rete neurale, un’architettura composta da unità di elaborazione disposte in modo da ricalcare la struttura a rete dei neuroni.
Questa rete è basata su BERT, un modello computazionale del linguaggio in grado di catturare anche la polisemia dei termini all’interno dei testi, e che raggiunge lo stato dell’arte in molti task di NLP.
I modelli come BERT sfruttano il cosiddetto meccanismo dell’attention, attraverso il quale la rete “pone l’attenzione” su tutti i termini della porzione di testo in esame, attivando alcune unità, alcuni “neuroni”, che ne conservano le informazioni durante tutto il processo di elaborazione.
Questa architettura è stata combinata dai ricercatori a un modello statistico detto Conditional Random Fields (CRF) che annota sequenze di testo: i dati prodotti da BERT sono quindi impiegati dal CRF per prendere delle decisioni, ovvero per stabilire se una certa sequenza di termini può essere annotata come un effetto collaterale o meno.
Prossimi sviluppi
Al momento il sistema estrae informazioni solo da Twitter, ma dovrebbero essere presto inclusi altri social nel monitoraggio.
“Tra le priorità che abbiamo individuato – fa notare Giuseppe Serra – c’è quella di far evolvere la piattaforma affinché possa anche servire da fact-checker: vorremmo sviluppare un modello che segnali in maniera automatica la possibile non veridicità di una notizia”.
Ma non solo: Il modello impiegato per analizzare i post sui vaccini, può essere adattato anche al monitoraggio degli effetti collaterali di altri farmaci.
Oltre la piattaforma
Gli interessi di Emmanuele Chersoni, Assistant Professor al Politecnico di Hong Kong vanno anche oltre le possibilità della piattaforma.
“Sarei curioso di vedere – spiega – come gli esseri umani processano una certa frase quando devono svolgere la stessa operazione che compie il nostro modello, ovvero individuare gli effetti collaterali in un tweet”.
Chersoni si occupa infatti di linguistica cognitiva, una branca della linguistica che studia i processi cognitivi alla base dell’utilizzo del linguaggio.
“Vorrei impiegare strumenti come l’eye-tracker per tracciare il movimento oculare. Chissà che tipo di corrispondenza esiste tra il modo in cui un essere umano legge per annotare un testo e i processi di elaborazione messi in atto dal meccanismo di attention della nostra rete neurale”.









